KMeans clustering on two attributes in data mining
By: Prof. Dr. Fazal Rehman | Last updated: March 3, 2022
How Is K-Means clustering performs on two attributes?
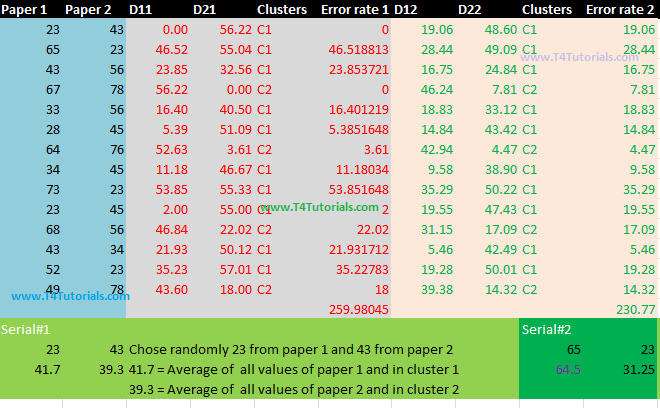
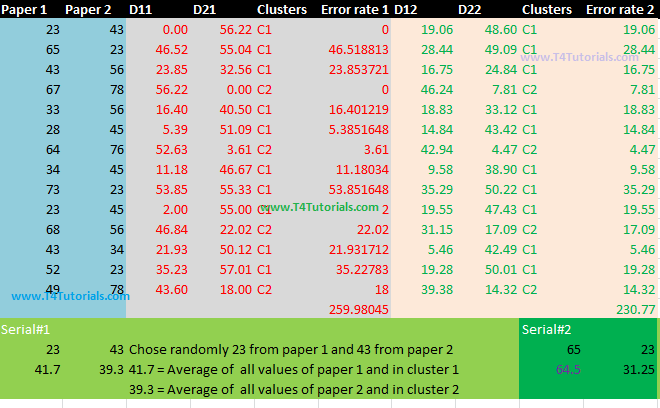
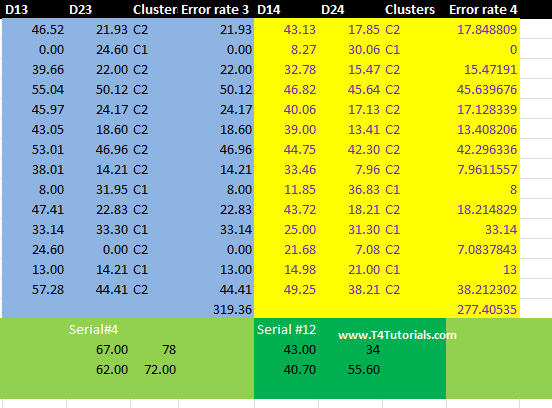
Lets start the discussion with an example. For example, we have 2 attributes;Paper1.Paper 2.First of all, randomly we will choose centroid values.Then calculates the distance between each value of paper 1 and paper 2.Next, Find the error rate.Repeat this all process until the error rate remains consistent in at least two last iterations or clusters stops to change further.Figure: k-mean clustering