Dimensionality reduction is the process in which we reduced the number of unwanted variables, attributes, and. Dimensionality reduction is a very important stage of data pre-processing.
Dimensionality reduction is considered a significant task in data mining applications.
For example, let’s start with an example. Suppose you have a dataset with a lot of dimensions (features or columns in your database).
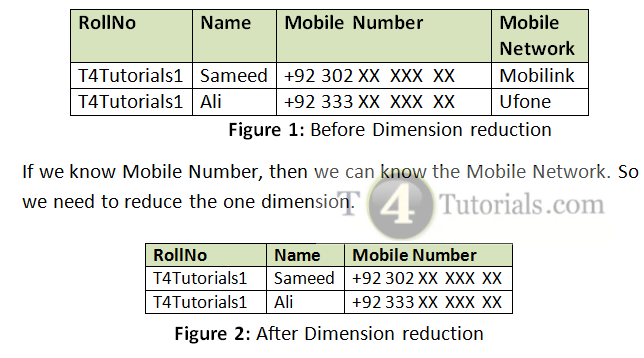
In this example, we can see that if we know the mobile number, then we can know the mobile network or sim provider. So, we reduce a dimension of mobile network. When we reduce the dimensions, then you can reduce those dimensions of attributes of data by combining the dimensions in such a way that it will not lose significant characteristics of the original dataset that is going to be ready for data mining.
Why Dimensions Reduction?
Curse of Dimensionality
“The Curse is an offensive word or phrase used to express anger or annoyance”.
The curse of dimensionality is a condition that occurs when we want to classify, organize, and analyze the high dimensional data.
When the number of dimensions increases, the distance between two independent points increases, and similarity decreases. This problem results in more errors in our final results after data mining.. When we are working on the data, especially big data, then a very large number of data points are there, so a lot of dimensions are possibly there. In this case, it’s practically impossible to get the wanted results and even if we suppose that it’s possible then it will give inefficient results.
- If we reduce the dimension, then it can be easy and more convenient to collect the data.
- Data is not collected only for data mining.
- Data accumulates at a good speed.
- Data preprocessing is an important task to do for better and effective data mining.
- Dimensionality reduction is an effective approach to collect less data but efficient data.
- Dimensionality Reduction is very helpful in the projection of high-dimensional data onto 2D or 3D Visualization.
- Dimensionality Reduction is helpful in inefficient storage and retrieval of the data and promotes the concept of Data compression.
- Dimensionality Reduction encourages the positive effect on query accuracy by Noise removal.
- Dimensionality Reduction reduces computation time. It fastens the time required for performing the same computations.
- Dimensionality Reduction is helpful to remove redundant features.
Application of Dimensionality Reduction
- Text mining
- Image retrieval
- Microarray data analysis
- Protein classification
- Face and image recognition
- Intrusion detection
- Customer relationship management
- Handwritten digit recognition
Major Techniques of Dimensionality Reduction
- Feature selection
- Feature Extraction (reduction)
Differences between the two techniques.
Feature Selection
Feature Selection is a process in which we choose an optimal subset of dimensions or features that can fulfill our requirements optimally.
It usually involves three ways:
- Filter
- Wrapper
- Embedded
Feature Extraction | Feature Reduction
Feature Extraction is a technique to reduces the data in a high dimensional space to a lower dimension space, i.e. a space with a higher number of dimensions to space with a lesser number of dimensions.
The different methods used for dimensionality reduction are mentioned below;
- Principal Component Analysis (PCA)
- Linear Discriminant Analysis (LDA)
- Generalized Discriminant Analysis (GDA)