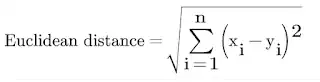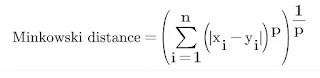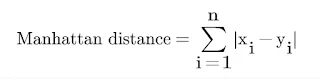By: Prof. Dr. Fazal Rehman | Last updated: December 26, 2023
Here i am sharing with you a brief tutorial on KNN algorithm in data mining with examples.
KNN is one of the simplest and strong supervised learning algorithms used for classification and for regression in data mining.
K- NN algorithm is based on the principle that, “the similar things or objects exist closer to each other.”
KNN is most commonly used to classify the data points that are separated into several classes, in order to make prediction for new sample data points.
In KNN algorithm ‘K’ refers to the number of neighbors to consider for classification. It should be odd value.
The value of ‘K’ in KNN algorithm must be selected carefully otherwise it may cause defects in our model.
Low Bias and High Bias KNN AlgorithmLow Bias KNN Algorithm:
If the value of ‘K’ is small then it causes Low Bias.
High Bias KNN Algorithm:
High variance. For example over fitting of model.
What happens when ‘K’ is very large in KNN Algorithm?
In the same way if ‘K’ is very large then it leads to High Bias, Low variance i.e. under fitting of model. There are many researches done on selection of right value of K, however in most of the cases taking ‘K’ = {square-root of (total number of data ‘n’)} gives pretty good result. If the value ‘K’ comes to be odd then it’s all right else we make it odd either by adding or subtracting 1 from it.
K-NN works well with a small number of input variables or large number of variables?
K-NN works nicely with a small number of input variables (p), but when the number of inputs becomes very large, then there are more chances of error in prediction.
It is based on the simple concept of mathematics to measure the distance between two data points in graph. We can use different distance measuring techniques for K-NN and some of the distance measuring techniques are mentioned below;
Euclidean Distance:
Minkowski Distance:
Manhattan Distance:
Euclidean Distance:Figure: Euclidean Distance KNN formulaMinkowski Distance:Figure: minokwsi KNN formulaManhattan Distance:Figure: manhattan KNN formulaWhich of the following is widely used?
Euclidean Distance
Minkowski Distance
Manhattan Distance
Euclidean Distance method is widely used as compared to the Minkowski Distance and Manhattan Distance.
K-NN Algorithm in data mining
Load the given data file into your program.
Initialize the number of neighbor to be considered ( i.e. value of ‘K’ must be odd).
Now for each tuples (entries or data point) in the data file we perform:
Calculate distance between the data point (tuple) to be classified and each data points in the given data file.
Then add the distances corresponding to data points (data entries) in given data file (probably by adding column for distance).
iii. Sort the data in data file from smallest to largest (in ascending order) by the distances.
Pick the first K entries from the sorted collection of data.
Observe the labels of the selected K entries.
For classification, return the mode of the K labels and for regression, return the mean of K labels.
If we try to implement KNN from scratch it becomes a bit tricky however, there are some libraries like sklearn in python, that allows a programmer to make KNN model easily without using deep ideas of mathematics.
Advantages and Disadvantage of KNN Algorithm
Advantages of KNN Algorithm
KNN algorithm is quiet easy.
KNN algorithm is simple to implement as it does not include much of difficult mathematics.
By using KNN algorithm, we can solve both classification and regression problem.
Disadvantages of KNN Algorithm
The KNN algorithm can be more slower as the size of data increases time to time.