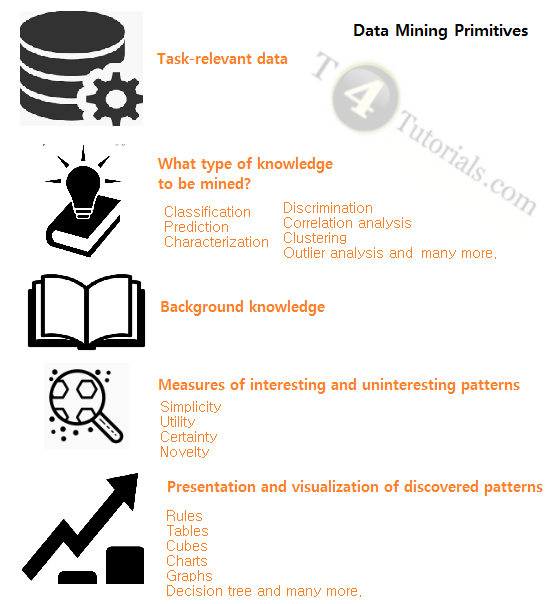
We can define a data mining query in terms of different Data mining primitives. Some of these are mentioned below;
Task-relevant data
This represents the portion of the database that needs to be investigated for getting the results. For example, suppose that you are a Sales Executive of a company XYZ in Germany and Russia. Suppose currently you want to mine the data for Germany. Now, the best choice is to mine the data just for Germany, rather than mining the data of the full database. In other words, we can say that we need to mine the relevant attributes of the database representing the data of Germany.
What type of knowledge to be mined?
We need to specify the data mining actions that need to perform on the data.
Some of these actions are mentioned below;
- Classification
- Prediction
- Characterization
- Discrimination
- Correlation analysis
- Clustering
- Outlier analysis and many more.
Let’s suppose that we want to explore the buying habits of customers in Germany, then we can choose to mine associations of different products that customers buy. We perform this when we want to know that if a customer buys product A, then what product is most likely he/she buy with product A.
Background knowledge
Background knowledge is useful for guiding the process of knowledge discovery and it is helpful when we want to evaluate the patterns.
Advantages of More Background knowledge
It is better to solve many data mining problems if we add more background knowledge. Some of the advantages are mentioned below;
Predictive models can become more accurate by adding more background knowledge.
Predictive models can reveal more interesting by adding more background knowledge.
RapidMiner Linked Open Data Extension is a methodology that can extend a dataset with additional attributes The prediction error of the data can be reduced by 10-50% with the addition of some additional attributes.
Disadvantages of More Background knowledge
When we add more background knowledge then it’s too long manual and slow work to Collect and integrate the background knowledge.
Measures of interesting and uninteresting patterns
The Interestingness measures are used to separate interesting and uninteresting patterns from the knowledge. These measures are helpful in the process of mining, or after discovery when we want to evaluate the discovered patterns. Each different knowledge may or may not have different interestingness measures.
Presentation and visualization of discovered patterns:
Users can select to view the knowledge with a multiple-way representation.
Some of the representations are mentioned below;
- Rules: Association rule mining
- Tables
- Cubes.
- Charts: Pie Charts, Mosaic or Mekko Charts, Population Pyramids, Spider Charts, and many more.
- Graphs: Line Graphs, Bar Graphs, and many more.
- Decision tree: A decision tree is a tree-like structure having three main parts, a root node, leaf nodes, and branches.
- The internal nodes represent a test on an attribute in the data set.
- The branch represents an outcome of a test.
- The leaf nodes are used to label a class. The node on the topmost position in the decision tree is the root node of the tree.